The CEO of Lemonade, Dan Schreiber, made the statement in a recent talk that:
“The future of insurance will be staffed by bots rather than brokers and AI in favor of actuaries.”
Despite sounding rather impressive, the Youtube video of the rest of Dan’s talk doesn’t really go into much detail to explain his thinking. That being said, this statement seems to be predicated on the view that actuarial science won’t evolve to embrace AI and bring the tools of modern statistical and machine learning into the everyday practice of actuaries. I personally think this view is inaccurate, and that actuaries practicing in “the future” will just as easily turn to a machine learning algorithm as they will to the traditional tools of the trade. Together with the domain specific knowledge of insurance that actuarial training brings, I think this will be a powerful combination that will serve the insurance industry well.
One reason I feel comfortable making this prediction is that the actuarial literature is starting to examine AI and machine learning, and how it can be applied to traditional actuarial problems. Many of the best examples that I have seen are from Professor Mario Wüthrich (who, together with his colleagues, is credited with the thinking and formula behind the Solvency II Reserving Risk formula). Some of his work includes applying deep neural networks to telematics data and machine learning approaches to the problem of IBNR reserving. Other recent papers include one applying deep auto-encoders to analyse population mortality in a Lee-Carter setup and another examining gradient boosted Tweedie models for pricing.
I plan to examine some of these new ideas in actuarial science on this blog in the next couple of posts and also provide code in R and Python on my Github account that will allow anyone who is interested to see how to apply these ideas practically. First up will be auto-encoders, which are a form of dimensionality reduction used to summarize high dimensional data in a low dimensional form. As an example of high dimensional data, think of a life table that has entries for the mortality rate for each age in the table. A life table with rates up to age 110 can be thought of a 110 dimensional vector. Although it is not a new idea to summarize a life table with a only a few parameters (the mortality laws, the Lee-Carter model using SVD and Brass’ Logit Transform spring to mind), recent work has shown that neural networks can estimate these summaries more accurately than traditional methods.
I also plan to build a section on my website that acts as a guide to this emerging field of actuarial science that I hope will be useful to other actuaries (and professionals) who want to understand how AI and machine learning can be applied to actuarial problems. As a start, some of the excellent material from Prof Wüthrich is available on his website.
Insurance seems to have become an exciting industry to work in these days and I am equally excited about the opportunities that lie ahead for actuaries and other insurance professionals.
This post is a continuation of the last two weeks and tries to find an estimate of impact of motor accident deaths on life expectancy in South Africa. A significant part of this impact could be eliminated by self-driving cars and the post two weeks ago looked at the possible benefits in the UK and the USA. Last week I discussed some of the issues encountered when dealing with demographic data in South Africa and this week proposes a simple approach that tries to avoid some of the issues that were discussed to derive the impact of motor accidents on life expectancy.
Caveat: Digging into these numbers, it seems to me that dealing with this properly needs much more than a blog post and could be the subject of detailed research. Indeed, much of the work has been done already in the National Burden of Disease study (Pillay-Van Wyk, Laubscher, Msemburi et al. 2014; Pillay-van Wyk, Msemburi, Laubscher et al. 2016) and the most this post can attempt to do is see what can be derived from the publicly available information. I recommend that anyone interested in mortality in South Africa go through this fantastically detailed study.
My guess is that the numbers in this post are a lower bound on what the true reduction in life expectancy due to motor accidents is.
If you want to consider the appropriateness of these numbers, please also read the section below “Conclusions and Limitations”.
The code for this post has been uploaded to my Github here, in the file “traffic mort – RSA.r”:
For the purpose of this post, I am going to try avoid the issue of incomplete reporting of deaths as much as possible. I am not aware of any demographic (i.e. mathematical) method that can correct incomplete reporting of deaths by cause, I am going to make the strong assumption that the level of completeness of reporting of deaths by cause is constant in each year i.e. there is no greater propensity to report a death due to one cause more than another. If this is the case, then some simple arithmetic shows that the ratio of deaths due to one cause to deaths due to another cause is an unbiased estimate of the true ratio and therefore we don’t need to correct the death data.
Important to note here is the study by Matzopoulos, Prinsloo, Wyk et al. (2015) who went through mortuary records in 2009 to work out the true number and cause of deaths due to injuries, including motor accident deaths. The Burden of Disease study (Pillay-van Wyk, Msemburi, Laubscher et al. 2016) used these numbers as an input into a calculation whereby they corrected for injury-specific completeness of reporting, which implies that the assumption made above is a little questionable.
To deal with the issue of mislabelled cause of death data, I am going to take the following approaches:
Firstly, hunt through the data to find causes of death that are not in the CDC list but probably represent motor accident deaths
Using these deaths, establish a cause-specific age profile and hunt though the rest of the data to see if we find any matches.
Try to cross-reference the WHO data with the Road Traffic Management reports on accident fatalities in South Africa.
I am then going to derive a set of factors for each age group and year which explain how many of the reported deaths are due to motor accidents.
Lastly, I am not going to try rederive my own set of mortality rates given the uncertainties in both the death and population data, but I am rather going to rely on modelled estimates of mortality from the Thembisa model (https://www.thembisa.org/). The Thembisa model seems to me to be the best publicly available model for this purpose and the project maintainers have made a very commendable effort to make the model and documentation available at their website. Using these estimates and the reduction factors discussed in the step before this, we will have everything we need to work out an adjusted life expectancy.
Data
I used three main sources of data. Like last week, the cause of death data is from the WHO Mortality database (http://www.who.int/healthinfo/statistics/mortality_rawdata/en/), which compiles death counts in 5-year bands by the ICD10 classification for a large number of countries around the world.
Secondly, I used the reports from the Road Traffic Management Corporation to compare the number of reported motor accident deaths in the WHO data to an external source. The reports are available here and contain many other interesting pieces of data:
Lastly, I used the Tembisa model outputs to provide mortality rates.
Coding
Similar to the last post, I used the Centre for Disease Controls classification of the ICD-10 codes to identify the deaths due to motor accidents. This classification can be found here: https://www.cdc.gov/nchs/data/nvsr/nvsr66/nvsr66_05.pdf
However, this seemed to capture an unrealistically small number of deaths. When I looked at the data a bit more, I realized that many of the counts in the ICD10 codes relating to traffic deaths were under less informative codes than the CDC coding allowed for:
Cause
Deaths
ICD Title
V89
162598
Motor- or nonmotor-vehicle accident, type of vehicle unspecified
V09
11890
Pedestrian injured in other and unspecified transport accidents
V19
708
Pedal cyclist injured in other and unspecified transport accidents
I added these three to the CDC list on the basis that most of the recorded motor accident deaths are probably lurking in these codes. I then worked out the percentage of deaths at each age accounted for by these deaths, producing the following plot:
The shape of these curves is quite different from those for the UK and the USA, which peak at the ages when people begin to drive:
Looking more closely at the plot for South Africa, one can see that in recent years, the pattern is shifting towards a peak at these ages too. This makes sense – as fewer AIDS deaths get recorded in recent years (with the impact of AIDS mortality falling in recent years, probably due to ARVs as discussed in Pillay-van Wyk, Msemburi, Laubscher et al. (2016)[1]), the impact of other causes is increasing.
More disturbing, though, is the fact that motor accidents don’t seem to be as much of an issue in South Africa, compared to the USA and UK, accounting for a maximum of about 7.5% of deaths compared to upwards of 40% in the USA at some ages.
Some more prior knowledge comes from Pillay-van Wyk, Msemburi, Laubscher et al. (2016) who show on page 646 of their study that road injuries were the ninth largest cause of death in South Africa in both 1997 and 2012.
A final hint that we are missing some deaths comes from the Road Traffic Management Corporation reports, which contain fatality numbers for each of the years since 2004. I pulled these numbers out of the reports, and produced the comparison shown below:
Year
Deaths
Crash Fatalities
Proportion
2004
5 026
12 778
39%
2005
5 279
14 135
37%
2006
5 546
15 419
36%
2007
5 995
14 920
40%
2008
5 470
13 875
39%
2009
5 550
13 768
40%
2010
5 511
13 967
39%
2011
5 027
13 954
36%
2012
5 250
13 528
39%
2013
5 544
11 844
47%
2014
5 786
12 702
46%
2015
6 171
12 944
48%
The table shows that only about 40-45% of the deaths registered by the RTMC are showing up in the WHO data. The RTMC uses a different reporting process than the deaths going into the WHO data and relies on reports issued by the police in the case of accidents. Could we perhaps be missing some of the deaths from the RTMC because we are missing some deaths in the WHO data due to poor coding?
Searching through the data
To look for some of the missing deaths, I calculated the age “signature” of the traffic deaths that we have already found, which I defined as the proportion of deaths in each age bucket for each sex in each year that we have coded as being due to motor accidents. This signature looked like the following plot.
I then searched through the WHO data and calculated the distance between the age signature for the motor deaths and each cause of death labelled by ICD10 code. The table below shows the results:
Country
Cause
Deaths
distance
South Africa
Y34
273496
30%
UK
X969
41
32%
USA
X940
1965
38%
USA
X930
2188
40%
USA
X708
3377
47%
USA
O960
490
51%
USA
X701
2454
51%
USA
X804
1052
53%
USA
X730
9945
53%
USA
X744
2488
55%
USA
X740
35822
56%
USA
X808
1033
57%
USA
X816
805
57%
USA
W776
73
57%
USA
X748
5357
57%
USA
O961
596
58%
USA
X718
1207
58%
USA
X702
667
59%
USA
X728
2077
60%
USA
W875
63
61%
It turns out that the closest match amongst the SA, USA and UK data is code Y34, which stands for “Unspecified event, undetermined intent”. The correspondence is quite good for both sexes, but a little bit out for females at the younger ages. The match is shown in the following plot (the lines represent the age signature of Y34 and the dots represent the signature shown above):
So I think it is a fair conclusion that some of the motor related deaths in South Africa land up in the WHO data under a “garbage” code. This is also in line with Matzopoulos, Prinsloo, Wyk et al. (2015) who found that the aggregate number of deaths in their study was not significantly different from the aggregate number due to external deaths in the Stats SA data (which feeds into the WHO dataset) but that deaths had been mislabelled.
Therefore, I transferred some of the deaths from cause Y34 into those related to motor accidents. I used the RTMC reports as the “true” number of deaths, which is another questionable assumption since Matzopoulos, Prinsloo, Wyk et al. (2015) actually found more motor accident related deaths than those reported by the RTMC. For this reason I view the number produced next as a lower bound, and discuss more in the conclusion.
The final proportions of deaths due to motor accidents I derived are as follows:
It can be seen that these are significantly higher than the proportions in the previous section.
Impact on Life Expectancy
The next step is to calculate the impact on life expectancy. I extended out the Thembisa mortality rates to age 110 using a Gompertz curve and then reduced the mortality rates in the Thembisa model by the proportions of the deaths due to motor accident discussed above. These curves for 2015 are shown in the following plot (the blip at age 90 is where the Gompertz curve joins the data and should be smoothed out), together with the curves adjusted for the impact of motor accidents:
The impact on life expectancy at birth is as follows:
Sex
Year
e0
e0 – no motor accidents
Increase
Male
2004
51.72
52.51
0.79
Male
2005
51.71
52.58
0.86
Male
2006
52.07
52.96
0.89
Male
2007
52.93
53.82
0.89
Male
2008
51.24
52.06
0.81
Male
2009
55.41
56.25
0.83
Male
2010
57.20
58.04
0.84
Male
2011
58.50
59.34
0.85
Male
2012
59.20
60.05
0.85
Male
2013
59.74
60.54
0.80
Male
2014
60.15
61.03
0.88
Male
2015
60.47
61.34
0.88
Female
2004
55.77
56.09
0.32
Female
2005
55.66
56.01
0.35
Female
2006
56.32
56.71
0.40
Female
2007
57.83
58.18
0.35
Female
2008
56.35
56.66
0.31
Female
2009
61.15
61.47
0.32
Female
2010
63.04
63.38
0.33
Female
2011
64.71
65.08
0.37
Female
2012
65.79
66.13
0.34
Female
2013
66.81
67.13
0.33
Female
2014
67.66
68.00
0.34
Female
2015
68.00
68.35
0.35
The gain in life expectancy for males is much higher than for females, which is due to two factors:
The higher mortality rates due to accidental death for males, compared to females
The bigger impact of motor deaths for males compared to females, as shown above
Translating these numbers into years of life lost due to motor accidents, using the reported 2015 birth cohorts from Stats SA, we get an 417 124 years of life for males and 163 157 for females.
Conclusion and Limitations
This post examined the impact of motor accident related deaths on mortality and life expectancy in South Africa. Like most exercises focussing on South African mortality that I have been involved in, it comes down to trying to work out how deaths have been reported and recorded.
The key assumptions that were made are:
some of the motor accident related deaths have been misreported under Y34
the RTMC reports are the true number of these deaths
all causes of death are reported with the same level of completeness
Matzopoulos, Prinsloo, Wyk et al. (2015) found that in fact, more deaths had been recorded by mortuary reports in 2009 than appeared in the RTMC reports. The difficulty I have in using their number in this type of armchair analysis is that we know the WHO data is not completely reported, so some part of the deaths that they found relates to the normal under-reporting of deaths in South Africa, and not the cause specific reporting issues. The fact that they found more deaths also invalidates the assumption that all deaths are reported at the same level of completeness but it is unclear to me how to correct the WHO data using their finding.
This represents a limitation of the analysis performed above and it seems to me that the gain in life expectancy derived in this analysis is probably too low.
This post showed that eliminating deaths due to motor accidents would be a big win for public health. The problem is that I imagine self-driving cars will not come to South Africa nearly as quickly as more developed countries and also I don’t imagine that the whole population would benefit immediately. Other challenges for self-driving cars in South Africa are likely to arise from the relatively poor road infrastructure. Therefore, the potential benefits to mortality will not be realized anytime soon.
References
Matzopoulos, R., M. Prinsloo, V.P.-v. Wyk, N. Gwebushe et al. 2015. “Injury-related mortality in South Africa: a retrospective descriptive study of postmortem investigations”, Bulletin of the World Health Organization93(5):303-313.
Pillay-Van Wyk, V., R. Laubscher, W. Msemburi, R.E. Dorrington et al. 2014. “Second South African National Burden of Disease Study: Data Cleaning, Validation and SA NBD List”, Cape Town: Burden of Disease Research Unit, South African Medical Research Council
Pillay-van Wyk, V., W. Msemburi, R. Laubscher, R.E. Dorrington et al. 2016. “Mortality trends and differentials in South Africa from 1997 to 2012: second National Burden of Disease Study”, The Lancet Global Health4(9):e642-e653.
[1] Quoting from page 651 of their study “We report a marked decline in HIV/AIDS and tuberculosis mortality since 2006, which can be attributed to the intensified antiretroviral treatment rollout for adults since 2005. According to the National Department of Health, more than 2 million people received antiretroviral therapy in 201231 versus an estimated 47 500 in 2004. The rollout of the prevention of mother-to-child transmission programme since 2002 has reduced infections and hence deaths in infants.”
Last week I posted about the impact of motor related accidents on mortality in the USA and UK and derived the increased life expectancy that would occur if self-driving cars eliminated the extra mortality from motor accidents. There was some interest expressed to me in considering the case of South Africa, and this post attempts to document some of the issues that need to be dealt with before this can be done successfully (next week’s post will cover the actual numbers for South Africa). These are some of the lessons I learned when I ventured out to explore mortality improvement in South Africa and I hope these will be useful for other actuaries or anyone else interested in this data, who may attempt to do similar work.
As an introduction to the challenges of working with demographic data in South Africa (and many developing countries, such as those in South America), it is worth spending some time considering the perfect counterpoint to the demographic data – which is, why AI and machine learning are enjoying their moment in the spot light. Most of the advances we see today in AI and machine learning are driven by the huge and relatively accurate datasets that are now common in most fields. These datasets might consist of labelled images of objects or user data collected from websites. Two of the major appeals of deep learning (by which I mean the modern approach to neural networks) are:
the performance of deep learning algorithms scales with the amount of data fed in, whereas other approaches to machine learning often don’t benefit from adding extra data once a certain amount of data has been used.
with enough data (and computing power), all one needs to do is feed data through an appropriate neural network architecture to get world class predictive performance, without spending time and effort trying to hand derive useful representations of the data.
Almost the exact opposite case is the demographic data that are used to derive mortality and other measures. In developing countries, this type of data is often inaccurate, incomplete, hard to access and available long after it is relevant. Before once can derive any sort of value from it, a large amount of data clean-up needs to be performed, generally assisted by ingenious demographic methods developed for these specific types of problems.
As a reminder of last week’s post, the plan eventually is to use the cause of death data to isolate deaths due to motor accidents and then rederive life expectancy without the impact of these deaths. To do this successfully, we will need to understand some of the issues with the death data in South Africa.
The code for this post has been uploaded to my Github here, in the file ‘garbage codes.r’:
In the rest of this post I am going to focus on some of the issues with the South African death and population data that need to be dealt with before a valid set of results can be derived. The post next week will discuss how I attempted to solve these problems.
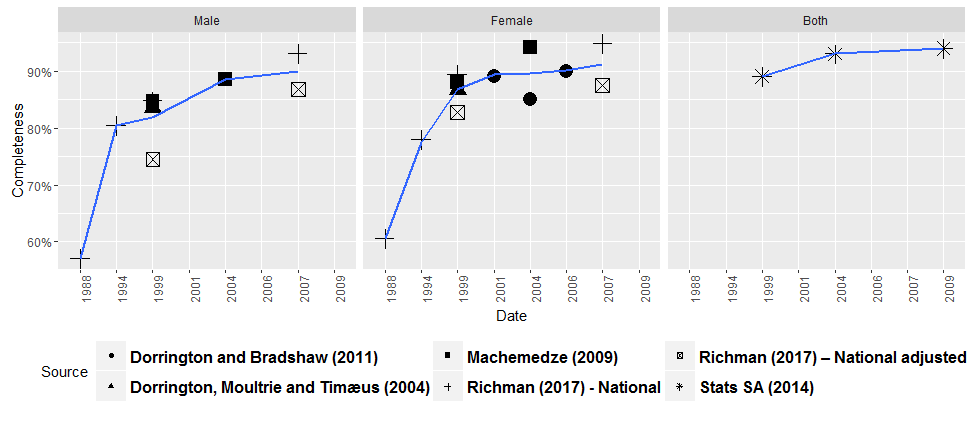
The first issue is that deaths in South Africa are not all reported. The image that follows shows various estimates of the completeness of reporting of deaths over time, as derived by various different studies. These studies have all applied a set of techniques known as the death distribution methods which use mathematical demography to reconcile the death data to population data and work out how many deaths are missing.
Most sources agree that completeness has improved over time, reaching about 90% towards 2010. Before the death data can be used for any purpose, the missing deaths need to be added back into the mix.
If anyone wants to find out more, a fantastic resource on the death distribution methods and other demographic techniques is available here:
The next major issue to tackle is that the cause of death data in South Africa suffer from mislabelling and garbage codes. As in the last post, I pulled the WHO cause of death dataset from the WHO website. In the following, I tabulated the major causes of death appearing in the data for South Africa:
Cause
Deaths
ICD Title
Garbage code
R99
2 268 174
Other ill-defined and unspecified causes of mortality
x
A16
1 787 058
Respiratory tuberculosis, not confirmed bacteriologically or histologically
J18
1 257 426
Pneumonia, organism unspecified
A09
815 196
Diarrhea and gastroenteritis of infectious origin
I64
767 534
Stroke, not specified as hemorrhage or infarction
E14
655 406
Unspecified diabetes mellitus
I50
563 446
Heart failure
Y34
553 978
Unspecified event, undetermined intent
x
D84
430 476
Other immunodeficiencies
I21
344 358
Acute myocardial infarction
B33
343 688
Other viral diseases, not elsewhere classified
B20
340 528
Human immunodeficiency virus [HIV] disease with infectious and parasitic diseases
X59
296 970
Exposure to unspecified factor
x
J44
240 726
Other chronic obstructive pulmonary disease
I11
234 216
Hypertensive heart disease
I10
225 752
Essential (primary) hypertension
C34
184 868
Malignant neoplasm of bronchus and lung
G03
175 520
Meningitis due to other and unspecified causes
J45
169 680
Asthma
R54
167 222
Senility
The largest number of deaths fall under R99, which stands for “Other ill-defined and unspecified causes of mortality”. Other suspicious codes are X59 and Y34. With our prior knowledge of the HIV/AIDS epidemic in South Africa, it is a fair guess that most of the deaths in the top 20 causes actually are from HIV/AIDS, and Birnbaum, Murray and Lozano (2011) and Bradshaw, Msemburi, Dorrington et al. (2016) attempt to quantify this with some clever work on the data. In next weeks post, I will discuss why I think quite a few traffic related deaths are actually sitting in code Y34.
Turning to the population data, there is disagreement amongst the various available estimates as to the size of the South African population. Below I show a plot from my research with estimates of the population aged 70 and older over time from various sources.
AltMYE – Alternative mid-year estimates, Dorrington (2013); ASSA – Actuarial Society of South Africa (2009); Stats SA – Statistics South Africa (2015); UNPD – United Nations Population Division (2013); USCB – United States Census Bureau (2015)
The black squares represent estimates from the model developed in my thesis, which estimates the population and mortality rates at the same time, using the death data as an input. A good resource to get acquainted with some of the issues at play here is Dorrington (2013). This work also contains a set of population estimates that are the most consistent with the last two censuses in South Africa, amongst those that I considered.
An obvious thing to do to try work out the size of the population is to look at the census data, but one has to be wary of census undercount. For example, I showed in my thesis that the censuses in South Africa before 2011 were undercounted relative to 2011:
National Males
National Females
1985
81%
88%
1991
90%
88%
1996
92%
94%
2001
97%
99%
This is why the estimates from my research in the previous plot appear higher than the earlier censuses.
Some miscellaneous issues:
Both the population and death data exaggerate the number of the elderly in South Africa, see for examples Machemedze (2009) and Richman (2017).
Both datasets suffer from age and year of birth heaping.
Birth registration is also uncertain in developing countries.
There are specific problems to consider when working with infant and maternal mortality.
After all of these problems, it will be time to discuss some solutions next week!
*** Footnote added on 14/1/2018
Diego Iturralde from Stats SA pointed out to me that the population estimates released by Stats SA in 2017 have been improved. I think it is fantastic that Stats SA has been working on improving these estimates, which (together with a document discussing them) are available from Stats SA on their website. A quick comparison of the estimates with the others shown above for the population aged 70+ is shown below.
These numbers are closer to those estimated in the censuses of 2001 and 2011 than the previous set of mid-year estimates I considered, but do not appear to be consistent with the 2011 census numbers for either sex, or with 2001 for males.
Birnbaum, J.K., C.J. Murray and R. Lozano. 2011. “Exposing misclassified HIV/AIDS deaths in South Africa”, Bulletin of the World Health Organization89(4):278-285.
Bradshaw, D., W. Msemburi, R. Dorrington, V. Pillay-van Wyk et al. 2016. “HIV/AIDS in South Africa: how many people died from the disease between 1997 and 2010?”, AIDS30(5):771-778.
I may be biased (for obvious reasons if you look at my LinkedIn profile), but I thought the new report on consumer perceptions of self-driving cars from @AIG is excellent. The report is here:
– Consumers in different countries have significantly different attitudes to self-driving cars – USA and UK vs Singapore
– Unlike some articles which assume that consumers will favor a subscription model for self-driving cars (a recent one from the FT is here – https://www.ft.com/content/c97eaa72-eaf8-11e7-bd17-521324c81e23), the most popular response to the question of ownership in the survey was that consumers would like to own a self-driving car!
– The article quotes a statistic that vehicle autonomy will reduce accidents by 90% by 2050 (interesting consequences for the change to life expectancy that I discussed in an earlier post)
An interesting development to watch is self-driving cars which I believe will have a massive impact on many areas of our day to day lives in the near future (especially for those of us working in Personal Lines insurance). Some of the interesting recent developments in this area have been:
My interest in the subject was sparked by some of the interesting deep learning applications for self-driving cars that Andrew Ng talks about in his recent Coursera course on Convolutional Neural Networks for computer vision.
This all got me wondering what the impact on mortality would be if self-driving cars reduced or eliminated the extra deaths caused by cars every year. In particular, who would this matter the most for – the young or the old, males or females – and what impact would this have on the shape of the mortality curve. It makes sense that it would take some time for self-driving cars to begin to have a noticeable effect on mortality, but if cars on the road would be autonomous, then it would be fair to assume that the majority of deaths relating to cars that currently appear in mortality data would be avoided.
To quantify the extent of the possible impact, I recalculated a mortality curve (more formally, a lifetable) for the USA and the UK with and without the impact of car related deaths. Obviously, self-driving cars will not immediately eliminate the entire burden of car related deaths, but this number represents an upper bound on the possible beneficial impact. The rest of this post will present the data sources used, the methodology I followed and the results.
The code for this post is available on my Github here:
I used two main sources of data. Firstly the cause of death data is from the WHO Mortality database (http://www.who.int/healthinfo/statistics/mortality_rawdata/en/), which compiles death counts in 5-year bands by the ICD10 classification for a large number of countries around the world.
For exposure data, I used the Human Mortality Database – the HMD – (http://www.mortality.org/) which has population numbers (as well as death counts and lifetables) for countries with relatively high quality demographic data. (Notably there is now also a Human Cause of Death database, but the information was not available at the level of granularity needed for these calculations).
Coding
After experimenting a bit, I landed on using the Centre for Disease Controls classification of the ICD-10 codes to identify the deaths due to motor accidents. This classification can be found here: https://www.cdc.gov/nchs/data/nvsr/nvsr66/nvsr66_05.pdf
Some high level reconciliations to other data sources indicate that the USA numbers are a little higher than those reported to the NHSTA (https://www-fars.nhtsa.dot.gov/Main/index.aspx) and the UK numbers are also higher (https://www.gov.uk/government/uploads/system/uploads/attachment_data/file/665162/ras40001.ods). One would need to have significant understanding of how each of these reporting systems work (in particular, how many deaths are reported to the NHSTA versus how many go into the USA vital registration and the same for the UK), so if anyone reading the post has some input, then please let me know!
Methodology
I performed the analysis in two parts. Firstly, I worked out a set of ratios indicating the percentage reduction in deaths in each five-year age band from the WHO data. Secondly, I applied these ratios to the death data at each individual age from the HMD and then calculated mortality rates using the HMD population data.
The reason two steps were needed is because I couldn’t find a comprehensive database with cause of death information in single year age bands.
Results
The following plot shows the percentage of total deaths attributable to motor accidents.
Both the USA and UK have fewer motor deaths over time at the relatively younger ages. I wonder if this is a real effect (due perhaps to improving safety technology in cars), or something not captured completely in the coding I used. The percentage of deaths attributable to motor accidents peak at the ages around which people first begin to drive. One possible insight here is that this is also an age when deaths due to “natural” causes are low, so “extra” accidental deaths at these ages will contribute significantly to the total number of deaths, whereas at the older ages, where “natural deaths” are high, the effect is less. Something else to consider is that driving ability probably improves with time.
After stripping the motor accident deaths out of the total deaths, I produced mortality rates (qx) as shown in the following plot. To smooth these out a little, I averaged the curves over five years (note that 2017 actually consists of data from only the 2015 year):
The major effect seems to be a flattening of the so-called accident hump between 20 and 30, with more impact in the USA than the UK. The declining impact of motor accidents over time is visible in the plots for both the USA and the UK.
The impact on life expectancy at birth is as follows:
Country_Name
Sex
Year_centre
ex
ex_no_traffic
Increase
UK
1
2002
76.20
76.44
0.24
UK
1
2007
77.49
77.71
0.22
UK
1
2012
78.94
79.06
0.12
UK
2
2002
80.77
80.85
0.07
UK
2
2007
81.75
81.82
0.07
UK
2
2012
82.78
82.82
0.04
USA
1
1997
74.13
74.68
0.55
USA
1
2002
74.64
75.21
0.58
USA
1
2007
75.70
76.24
0.54
USA
1
2012
76.65
77.08
0.43
USA
1
2017
76.62
77.06
0.44
USA
2
1997
79.56
79.85
0.29
USA
2
2002
79.86
80.15
0.28
USA
2
2007
80.74
80.98
0.25
USA
2
2012
81.45
81.65
0.19
USA
2
2017
81.47
81.67
0.20
Immediately noticeable is the declining impact of motor accidents on life expectancy with time, for both countries and sexes. If we take 2012 as the most robust recent estimate, then the biggest beneficiaries of eliminating motor accidents would be males in the USA.
I recently read a blog post from Bill Gardner (https://theincidentaleconomist.com/wordpress/us-life-expectancy-declined-again-how-much-does-that-matter/) who frames a change in life expectancy in a clever way, by working out the number of years of life gained or lost for the current birth cohort due to a change in life expectancy. With this idea in mind, a gain in life expectancy of 0.44 is a highly significant improvement representing about 870 000 years of life gained for the 2012 male birth cohort.
Conclusion
This post examined the impact of motor accident related deaths on mortality and life expectancy in the USA and the UK, to provide a view of what the maximum possible impact of introducing self-driving cars, which presumably would eliminate most of the burden of motor accident related deaths, on public health would be. Of the four groups considered, the biggest beneficiaries would be males in the USA, with about 870 000 years of life gained if motor accidents were eliminated completely.
The post did not try to quantify how much or how quickly these benefits would be realized and it seems this would be quite speculative sitting here at the beginning of 2018. The post also ignored second order effects on mortality, such as the fact that people would probably have more time to spend on pursuits other than driving when self-driving cars become a reality and the fact that the gains in life expectancy could be partially offset by other competing risks.
I found it interesting that the impact on life expectancy is lower in the UK than the USA, and it would be worthwhile to reproduce the analysis for all of the countries in the HMD.