Last week I posted about the impact of motor related accidents on mortality in the USA and UK and derived the increased life expectancy that would occur if self-driving cars eliminated the extra mortality from motor accidents. There was some interest expressed to me in considering the case of South Africa, and this post attempts to document some of the issues that need to be dealt with before this can be done successfully (next week’s post will cover the actual numbers for South Africa). These are some of the lessons I learned when I ventured out to explore mortality improvement in South Africa and I hope these will be useful for other actuaries or anyone else interested in this data, who may attempt to do similar work.
As an introduction to the challenges of working with demographic data in South Africa (and many developing countries, such as those in South America), it is worth spending some time considering the perfect counterpoint to the demographic data – which is, why AI and machine learning are enjoying their moment in the spot light. Most of the advances we see today in AI and machine learning are driven by the huge and relatively accurate datasets that are now common in most fields. These datasets might consist of labelled images of objects or user data collected from websites. Two of the major appeals of deep learning (by which I mean the modern approach to neural networks) are:
- the performance of deep learning algorithms scales with the amount of data fed in, whereas other approaches to machine learning often don’t benefit from adding extra data once a certain amount of data has been used.
- with enough data (and computing power), all one needs to do is feed data through an appropriate neural network architecture to get world class predictive performance, without spending time and effort trying to hand derive useful representations of the data.
Almost the exact opposite case is the demographic data that are used to derive mortality and other measures. In developing countries, this type of data is often inaccurate, incomplete, hard to access and available long after it is relevant. Before once can derive any sort of value from it, a large amount of data clean-up needs to be performed, generally assisted by ingenious demographic methods developed for these specific types of problems.
As a reminder of last week’s post, the plan eventually is to use the cause of death data to isolate deaths due to motor accidents and then rederive life expectancy without the impact of these deaths. To do this successfully, we will need to understand some of the issues with the death data in South Africa.
The code for this post has been uploaded to my Github here, in the file ‘garbage codes.r’:
https://github.com/RonRichman/traffic_mortality
What are the data issues?
In the rest of this post I am going to focus on some of the issues with the South African death and population data that need to be dealt with before a valid set of results can be derived. The post next week will discuss how I attempted to solve these problems.
The first issue is that deaths in South Africa are not all reported. The image that follows shows various estimates of the completeness of reporting of deaths over time, as derived by various different studies. These studies have all applied a set of techniques known as the death distribution methods which use mathematical demography to reconcile the death data to population data and work out how many deaths are missing.
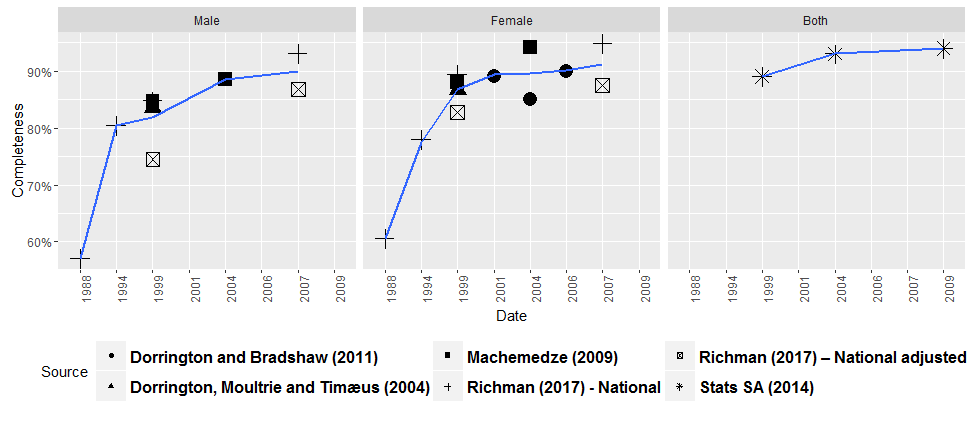
Most sources agree that completeness has improved over time, reaching about 90% towards 2010. Before the death data can be used for any purpose, the missing deaths need to be added back into the mix.
If anyone wants to find out more, a fantastic resource on the death distribution methods and other demographic techniques is available here:
http://demographicestimation.iussp.org/
There is also a recent R package here:
https://cran.r-project.org/web/packages/DDM/index.html
The next major issue to tackle is that the cause of death data in South Africa suffer from mislabelling and garbage codes. As in the last post, I pulled the WHO cause of death dataset from the WHO website. In the following, I tabulated the major causes of death appearing in the data for South Africa:
| Cause | Deaths | ICD Title | Garbage code |
| R99 | 2 268 174 | Other ill-defined and unspecified causes of mortality | x |
| A16 | 1 787 058 | Respiratory tuberculosis, not confirmed bacteriologically or histologically | |
| J18 | 1 257 426 | Pneumonia, organism unspecified | |
| A09 | 815 196 | Diarrhea and gastroenteritis of infectious origin | |
| I64 | 767 534 | Stroke, not specified as hemorrhage or infarction | |
| E14 | 655 406 | Unspecified diabetes mellitus | |
| I50 | 563 446 | Heart failure | |
| Y34 | 553 978 | Unspecified event, undetermined intent | x |
| D84 | 430 476 | Other immunodeficiencies | |
| I21 | 344 358 | Acute myocardial infarction | |
| B33 | 343 688 | Other viral diseases, not elsewhere classified | |
| B20 | 340 528 | Human immunodeficiency virus [HIV] disease with infectious and parasitic diseases | |
| X59 | 296 970 | Exposure to unspecified factor | x |
| J44 | 240 726 | Other chronic obstructive pulmonary disease | |
| I11 | 234 216 | Hypertensive heart disease | |
| I10 | 225 752 | Essential (primary) hypertension | |
| C34 | 184 868 | Malignant neoplasm of bronchus and lung | |
| G03 | 175 520 | Meningitis due to other and unspecified causes | |
| J45 | 169 680 | Asthma | |
| R54 | 167 222 | Senility |
The largest number of deaths fall under R99, which stands for “Other ill-defined and unspecified causes of mortality”. Other suspicious codes are X59 and Y34. With our prior knowledge of the HIV/AIDS epidemic in South Africa, it is a fair guess that most of the deaths in the top 20 causes actually are from HIV/AIDS, and Birnbaum, Murray and Lozano (2011) and Bradshaw, Msemburi, Dorrington et al. (2016) attempt to quantify this with some clever work on the data. In next weeks post, I will discuss why I think quite a few traffic related deaths are actually sitting in code Y34.
Turning to the population data, there is disagreement amongst the various available estimates as to the size of the South African population. Below I show a plot from my research with estimates of the population aged 70 and older over time from various sources.

AltMYE – Alternative mid-year estimates, Dorrington (2013); ASSA – Actuarial Society of South Africa (2009); Stats SA – Statistics South Africa (2015); UNPD – United Nations Population Division (2013); USCB – United States Census Bureau (2015)
The black squares represent estimates from the model developed in my thesis, which estimates the population and mortality rates at the same time, using the death data as an input. A good resource to get acquainted with some of the issues at play here is Dorrington (2013). This work also contains a set of population estimates that are the most consistent with the last two censuses in South Africa, amongst those that I considered.
An obvious thing to do to try work out the size of the population is to look at the census data, but one has to be wary of census undercount. For example, I showed in my thesis that the censuses in South Africa before 2011 were undercounted relative to 2011:
| National Males | National Females | |
| 1985 | 81% | 88% |
| 1991 | 90% | 88% |
| 1996 | 92% | 94% |
| 2001 | 97% | 99% |
This is why the estimates from my research in the previous plot appear higher than the earlier censuses.
Some miscellaneous issues:
- Both the population and death data exaggerate the number of the elderly in South Africa, see for examples Machemedze (2009) and Richman (2017).
- Both datasets suffer from age and year of birth heaping.
- Birth registration is also uncertain in developing countries.
- There are specific problems to consider when working with infant and maternal mortality.
After all of these problems, it will be time to discuss some solutions next week!
*** Footnote added on 14/1/2018
Diego Iturralde from Stats SA pointed out to me that the population estimates released by Stats SA in 2017 have been improved. I think it is fantastic that Stats SA has been working on improving these estimates, which (together with a document discussing them) are available from Stats SA on their website. A quick comparison of the estimates with the others shown above for the population aged 70+ is shown below.

These numbers are closer to those estimated in the censuses of 2001 and 2011 than the previous set of mid-year estimates I considered, but do not appear to be consistent with the 2011 census numbers for either sex, or with 2001 for males.
References
Actuarial Society of South Africa. 2009. Aids and Demographic Model 2008. Cape Town: ASSA. http://www.actuarialsociety.org.za/Societyactivities/CommitteeActivities/DemographyEpidemiologyCommittee/Models.aspx.
Birnbaum, J.K., C.J. Murray and R. Lozano. 2011. “Exposing misclassified HIV/AIDS deaths in South Africa”, Bulletin of the World Health Organization 89(4):278-285.
Bradshaw, D., W. Msemburi, R. Dorrington, V. Pillay-van Wyk et al. 2016. “HIV/AIDS in South Africa: how many people died from the disease between 1997 and 2010?”, AIDS 30(5):771-778.
Dorrington, R.E. 2013. Alternative South African mid-year estimates, 2013. CARe Monograph No. 13. Cape Town: Centre for Actuarial Research, University of Cape Town. http://www.commerce.uct.ac.za/Research_Units/CARE/Monographs/Monographs/Mono13.pdf.
Machemedze, T. 2009. “Old age mortality in South Africa.” Unpublished thesis, Cape Town: University of Cape Town.
Richman, R.D. 2017. “Old age mortality in South Africa, 1985-2011.” Unpublished thesis, Cape Town: University of Cape Town.
Stats SA. 2015. Mid-year population estimates. P0302. Pretoria: Statistics South Africa.
United Nations. 2013. World Population Prospects: The 2012 Revision. New York: Population Division, Department of Economic and Social Affairs.
US Census Bureau. 2015. International Database. Washington DC: International Programs Center.